
Wrestle Wrun – Starting a New Project
I have been meaning to get back into writing since my Multi-Threaded Programming series got derailed due to AltDevBlogADay going down (and just being busy with work and life in general). I also took a bit too long of a hiatus with the Super Mario Cuckoo project so I have been avoiding going back to it due to the ramp-up needed to remember how I was doing everything (plus I would love to possibly convert it to use Vulkan, even though it would be overkill). However, I have recently picked up a side project which has been holding my attention quite well and wanted to talk about some of the interesting decisions and challenges that I have been facing there.
One thing that makes this project unique is that I am not the sole person responsible for handling everything. This makes it much harder for me to just put it on the back-burner and move on with life. It is also not a project that I intend to write everything from scratch on. Starting with a blank slate is very good for initial learning purposes, but after you’ve written basic texture handling and drawing code for the “upteenth” time, it can be a little hard to keep up the motivation.
So with that little introduction out of the way, let me introduce you to WrestleWrun!
![]()
Overview
The main goal of this series is to discuss the technical decisions that are going on with WrestleWrun, a wrestling themed runner for mobile platforms. I will be writing this series alongside development, so there may be additions or alterations to previous content if I have to revisit something further down the road. I also hope to help give readers some insight in to my development process. Hopefully it will help teach people what can go on with the development of a game as well as why I chose to go with the solutions that I did. In addition to that, this might also help spread some awareness of the project, so then it will have a bit more of an audience upon its release!
The Starting Story
I’ve always been a big fan of River City Ransom (RCR) on the NES. I never owned the original game, but I would rent it often. I remember that I used graph paper to draw the pixelated characters back in school (probably using Nintendo Power or something as reference, the internet wasn’t much of a thing back then). In college, I worked for a little bit on a copycat game called Purdue University Payoff starring myself and my friends that I never finished. I frequently downloaded RCR to play around with it using emulation just for fun, and purchased it on the Virtual Console on the Wii as soon as it was released there. I certainly have logged many, many hours playing in that digital city.
So when I heard that there was a kickstarter to fund the sequel, I jumped at the chance to help get it off the ground. I checked out the forums every now and then and was always interested in the artist updates that showed the sprites being created (also the engine updates, but those weren’t nearly as frequent). On one particular forum topic, it was asked if anyone in the forums had any involvement in the video game industry, since some of the posts that people were making seemed well-informed about the going-on process of making a game. I offered up that I was a professional programmer for ten years now and had a hand in many big-name games. Shortly after doing so, I was messaged privately by the artist that he was looking for a programmer to help with a side project he had. It was going to be a mobile project and he already had a lot of the art for it so he just needed someone to add all the engineering bits to make it a game.
I haven’t worked on a mobile game yet, and I enjoy games with pixelated graphics with an old school feel. So I agreed to devote a good chunk of my limited free time to helping him out. I thought it would be a valuable learning experience since I have always wanted to mess around with programming for a phone. Plus this way I wouldn’t have to deal with the art and design stuff much since I find that I lose a decent amount of motivation when I have to tackle those areas in excess. Additionally, having another person whom is depending on me is always a plus since it means I just can’t idly put everything off on a whim.

Choosing An Engine
With any new project comes the decision on how to choose an engine. Typically, for personal stuff I decide to write my own. However, seeing as I have little experience with mobile and I’d really like to get to the game making part as quickly as possible, I made the decision to go with another engine instead.
I wanted an engine that would work on iOS, Android, and Windows. The first two are obvious since those are the platforms that we want the game to actually be on. Windows is so that I could easily work with it there and add debug modes and other such things that I wouldn’t want on the phone version. I also didn’t have any phones that I really wanted to develop with on just starting out, so being able to run the game on the development computer was a necessary requirement.
It would also be a big plus if it was open source. Part of this is to help with learning and debugging, so that I can see exactly what is going on and how they do things. I don’t generally like big black boxes that claim to do everything you need to do. This mistrust partially comes from my day job, where I am spending most of my time fixing existing engines. There is also the case that I don’t want to feel constrained by what the engine can do. If there are features that I want to add, or areas that I want to modify, then I want the capability to do so. Having the source also assists with debugging as I can see what exactly is happening.
Naturally, it being easy to use and having content tools available for it (or that could work with it) is also a big requirement. I don’t want to have to spend all my time writing the tools as that can get tedious. I’m here to make a game, not another process.
So with all those requirements, I settled on Cocos2D-X. The only part here that was lacking was some of the tool support. This is still being very much actively developed, so there are some parts that aren’t quite at the level I would like. But the biggest tool is the level editor, and I am able to make use of Tiled for this. For animation I am getting the timings and frame information from GIF files, and putting that info in JSON files in a custom format. Since we are just using simple sprite flipbook animation, this is working out well. Same goes for UI. So I am not using any of the provided Cocos2D-X tools currently nor plan to.
 Next Time
Next Time

For the next blog post, I am going to focus on the collision system that I am implementing. I haven’t messed around with collision much before and it has been an interesting time figuring it out as I go along. See you next time!
Multi-Threaded Programming 5: A Lock-Free Queue Implementation
In the last post, we showed an example of a locking queue that used two locks in order to safeguard against being used by multiple threads. For this one, we are going to see what it takes in order to turn that into a lock-free queue and discuss why each of those changes has to take place.
Again, this is implemented using C++ and uses C++11 techniques compiling under Visual Studio Express 2013. This is partially a pet project to get more familiar with the C++11 conventions of doing things, so let me know of any thoughts regarding how I am doing in that regard.
Disclaimer: Any code that is provided is for learning purposes only. I make no guarantees that it will work for your specific project or platform. It has been subjected to some standard tests that it has passed on two x86/64 systems (one Intel and one AMD). All code is released under the MIT license, so feel free to use it however you see fit.
I strongly recommend reading the previous post if you have not, as this builds off that one. If you want to read that or any of the other things that I have covered, then here are the links to my series:
- Multi-Threaded Programming 1: Basics
- Multi-Threaded Programming 2: Communication
- Multi-Threaded Programming 3: Locking, Lock-Free, Wait-Free
- Multi-Threaded Programming 4: A Locking Queue Implementation
Unbounded Lock-Free Queue
We are going to stick with using a queue so that you can easily see the changes that have to be made in order to safely remove the locks. This leads to a lot more complexity and fragility, since everything has to happen in a specific order to guarantee that things keep working the way you expect. We will stick with an unbounded queue still, which will keep memory allocation as part of the implementation. Depending on the allocator that you are using, this may include locks, so you could easily argue that this isn’t a true lock-free implementation. However, there are memory allocators that make heavy use of thread local storage (such as Intel’s TBB allocator) that avoid these locks in most cases. I am also not protecting against possible ABA issues, mainly because I haven’t encountered them in my testing yet and so want to hold off on introducing code that would prevent that situation. In the next post, I hope to tackle these issues.
The basic design and logic of the queue remains the same as before. Again, this is to try and provide the reader with implementations that are as identical as possible except for their locking strategy. The interface to the queue is also likewise consistent. I am also sticking with using an int datatype for the examples, but will provide links to the full templatized code at the bottom. So stating that, let us look at what needs to change for a lock-free strategy.
Enqueue
As with our previous implementation, the first thing we do is allocate a node to store our data into. Then you will notice that we enter an infinite loop, which is a common strategy with lock-free code. While locking code will often loop waiting for a certain condition to be met, lock-free typically wants to at least make some progress with each iteration of the loop. If it is interrupting another thread, then a lock-free algorithm may help the interrupted thread get its work partially finished, so that when the current thread loops again it has everything in place to properly do its job. With our enqueue this may happen if we interrupt a thread which has added a node to the end, but not yet had the chance to update the tail. If the current thread notices the queue in this state, it will properly update the tail and then attempt to add its node.
Anyway, when we are allocating our node you will notice that we release the data from the unique_ptr instead of moving it. This is because the implementation of unique_ptr is not thread-safe, so we need to store the data directly by pointer. We could store it using a shared_ptr, which is thread safe, if so desired, but I am not doing that because the node is completely contained within the queue. Because of this, I know that nothing else will be touching the data or its location and so can use normal pointers throughout and save on some performance.
At the beginning of our loop, we get local copies of our tail and its next value (which should be nullptr). Because there aren’t any locks, the state can change at any moment, so we need to verify everything each step of the way. This is why we check to make sure our tail is still our local value and that it is pointing to nullptr as its next value. We then verify this yet again via a compare_exchange (which is a Compare-And-Set atomic operation originally discussed a few posts ago) when we go to set the next value to the node that we are adding to the queue. If this succeeds, then all that is left to do is to set the tail to our new node. However, if that compare_exchange doesn’t work, then all it means is that another thread already did that which is fine by us.
A quick note: Since this is intended for x86-64 which has strong memory ordering guarantees, then there actually isn’t any difference between the weak and strong versions of compare_exchange. However, if this were to be used on a platform with a weaker memory model, then I believe the way it is coded would be the best way to implement them.
Dequeue
For dequeuing our data using a lock-free approach, again we begin with an infinite loop. This time we store off the head value, the tail, and node that we wish to get the data from. With our locking implementation, we didn’t have to worry about the tail at all. However we have to account for the fact that something could be in the middle of adding to the list while we are attempting to remove from it, and so we might be in the best position to finish their work. We check for this possibility after discounting the fact that the queue is empty.
However, if there are nodes to get, then we find out where our data will be located, then attempt to remove the first node. Only if that succeeds can we delete the former head node and return the proper data. If we were to attempt to remove the head before finding out where the data was, then we could run into a situation where another thread then removes our data containing node and deletes it before we have a chance to get at it.
Node
Our node looks similar, but as mentioned earlier we are using a normal pointer to refer to our data. The other big difference is the use of std::atomic to refer to our next node. This is because we need to do atomic operations on our data in order to make our algorithm lock-free. It also enforces that we use the appropriate memory barriers when accessing our data. Because we are running on an x84-64 implementation, we only need to worry about the CPU reordering writes. This isn’t too important to protect against in this particular case because we do all writes as atomic operations, which won’t be reordered. The compiler might reorder reads or writes, however, so this is still somewhat useful for us so we make sure we aren’t surprised by any optimizations that it might do. So using the atomic variable type helps enforce the intended behavior for us no matter what we are programming for.
Recap and Next Time
As you can see, getting the ordering of lock-free algorithms correct is something that needs to be closely paid attention to. Moving to lock-free effectively squares your problem space, since you have to consider what every other thread might be doing at any point in the code. Handling this can be quite difficult, and it also means that you can implement some very subtle bugs even despite the best of care. So lock-free stuff should only be used in areas where there is a lot of overlapping thread traffic and you need the performance gain. But I hope these examples helped illuminate some of the processes that go on behind what is involved when writing lock-free code.
Next time we are going to look at how our locking and lock-free code operate in terms of performance. We will also see if we can get some more performance out of them by restricting the number of nodes since in games we generally have a good idea of how many nodes we might be working with, and how that might introduce other complexities.
Full Source
The full source for this can be obtained at the links below. This is a more generic, template based version of the code posted above so hopefully it will be a bit more useful for you.
Multi-Threaded Programming 4: A Locking Queue Implementation
You can also view this post on AltDevBlogADay!
We covered the basic differences between the various multi-threaded techniques to protect our shared data in the last post. Now lets look at some code that will implement a locking technique. I will implement this using C++ and will use some C++11 techniques compiling under Visual Studio Express 2013. This is also partially a pet project to get more familiar with the C++11 conventions of doing things, so if you see any ways listed to do things better using the new parts of the standard, please let me know 🙂
Disclaimer: Any code that is provided is for learning purposes only. I make no guarantees that it will work for your specific project or platform. It has been subjected to some standard tests that it has passed on two x86/64 systems (one Intel and one AMD). All code is released under the MIT license, so feel free to use it however you see fit.
If you want to read up on other things that I have covered, then here are my previous posts in this series:
- Multi-Threaded Programming 1: Basics
- Multi-Threaded Programming 2: Communication
- Multi-Threaded Programming 3: Locking, Lock-Free, Wait-Free
Unbounded Locking Queue
For this I am going to demonstrate using a queue. I chose this because it is a simple, useful data structure that everyone reading this should be familiar with. This simplicity also lends itself well to understanding and being able to easily follow what happens when we move this to a lock-free implementation in the next post.
It will be unbounded, so that it can grow to fit the size of anything we need to store in it. We are going to protect our shared data through locking by using a mutex. We will have a head node which is always valid but isn’t considered to have relevant data, and a pointer to a tail node which represents the end. So in the case when the head has a empty next pointer (or the head and tail both reference the same data), we know we have an empty list on our hands.
By always having a valid node, we can skip checking to see if head or tail pointers are null, at the cost of having only an allocation of an extra node. This also allows us to separate the enqueue and dequeue functions so that we can have separate mutexes for each operation, so then we don’t need to prevent enqueuing while dequeuing is occurring, and vice versa.
Under the hood, this is implemented as a linked list. This is reasonable since we are only ever adding to the tail and removing from the head and never traversing. This does incur the cost of an allocation for each enqueue, but we are not concerning ourselves too much with performance at this stage, so that is acceptable.
In the examples I am assuming that we only need to store an int (the data type is irrelevant for the actual algorithms), but in the code link at the bottom I have a template based version that I would actually recommend using.
Enqueue
Our enqueue function is very straightforward. It will allocate a new node to store our data in to. First we will begin by locking this with our enqueue mutex, preventing anything else from being added until we are done. Technically, we can do the allocation before this lock because that is a local operation and doesn’t affect any shared data. The lock_guard construct will automatically release the lock when it goes out of scope, so that we don’t need to worry about a deadlock situation where it never gets released.
Once we have our new node, we append it to the list by having the tail’s node set it to its next reference. Then we complete the operation by setting the tail as our new node.
Dequeue
Our dequeue likewise is easy to understand and follow. We immediately start by locking with our dequeue mutex so that no other dequeues can occur. We then check for the case where we are empty and return null if this is the case. When that isn’t the case we know that we have valid data to get and so we obtain it. We remove our old node from the list by setting the head to its next node and return the data to the caller. Since we are making use of automatic referencing we don’t need to worry about cleanup since that will happen automatically for us.
Node
There isn’t anything too special about our Node class. It is simply a container that holds onto the data that was placed in the queue with a reference to the next node. While I have it only accepting a unique_ptr for SetNext, I have the actual _next as a shared_ptr because we can get multiple references due to the tail in the main LockingQueue class.
Test
Now we have one of my tests that I used to make sure that the code I was posting actually worked. I am also posting this to give you an example of how this queue can be used by multiple threads (granted in an arbitrary way, but the concept remains).
All this code is doing is setting up separate threads for reading/dequeuing and writing/enqueuing to our queue. I split the amount of writing evenly between the threads as well as the amount of work that will be done by the reading threads. This is just to verify that everyone is getting a chance to do some work. So I simply split the data into separate arrays, one for each writing thread. Then I create my threads and let them do their thing. Afterwards, I verify that everything was processed successfully.
Next Time
For the next time we are going to look at a lock-free version of our unbounded queue. This will add quite a bit of complexity to our simple, humble queue here, but not enough to make it unmanageable. As you will see, the order of operations is extremely important when it comes to dealing with lock-free algorithms.
After that, we will do some profiling on our two implementations and see how they compare. We will also see if there is anything that can be done to optimize them (hint: there will be). Talk with you then!
Full Source
The full source for this can be obtained at the links below. This is a more generic, template based version of the code posted above so hopefully it will be a bit more useful for you.
Multi-Threaded Programming 3: Locking, Lock-Free, Wait-Free
You can also view this post on AltDevBlogADay!
Now I want to cover the basic terminology used when talking about concurrent algorithms. This will be helpful so that you are familiar with the available techniques you have when you have multiple threads operating together. The term concurrent itself refers to an algorithm that can scale from being synchronous on a single thread to utilizing multiple threads at the same time. The terms I am going to cover also exist independently of any architecture, though the actual implementation will vary due to the underlying hardware differences. I am going to cover them in order of increasing difficulty to implement, so if you are interested in implementing an algorithm of your own, I would suggest starting with the simplest implementation and moving on only as needed.
If you want to read up on other things that I have covered, then here are my previous posts in this series:

Locking
In the previous post, we ended with an example of a mutex lock. This is the easiest and most straightforward method available in order to restrict access to a particular area of code for only a single thread at a time. However, as you may have surmised, it will also have the worst performance when dealing with many threads all accessing the same area at once. This is because the threads are restricted to operating serially, so you basically have given up on the performance benefits of using multiple threads for the area where you lock. But if it is an area that is accessed infrequently, or there is only a small chance that multiple threads will be in the locked area at the same time, it can easily be a “good enough” solution.
Locking is a good first step when you are dealing with data that can be read and modified by multiple threads. As we saw with the explanation of caches, when you modify data on one thread that change will quickly propagate to other threads that then read that data. However, the trickiness lies in the fact that these modifications can occur at any point within your algorithm. So by forcing the algorithm to operate in a serial manner we prevent any unexpected changes that can occur and disrupt what we expect to happen.
While debugging mutex locks can be fairly simple (as far as threading problems go), there are several ways that things can go wrong. If you are using locks and find that program has stopped responding, simply pause it and examine it in the debugger. Chances are that one of the following three things has occurred.
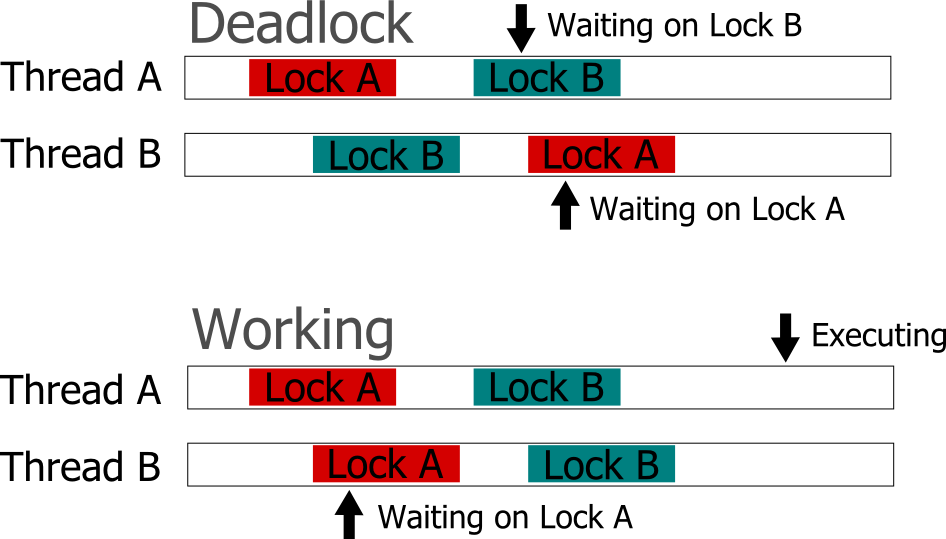
The first pitfall you might have fallen into is what is referred to as a deadlock. This occurs when the operation of your program results in such a manner where a lock is obtained but is never released. This causes your program to halt because no further progress can be made because all the threads are waiting on something that is never going to happen.
One cause of this can be due to not acquiring locks in the same manner in different places in your code. So if you acquire Lock A then Lock B in one place and Lock B then Lock A in another, you can get in a situation where one has Lock A locked and tried to lock Lock B, but can’t because Lock B has already been acquired. Since it has Lock A already, the thread that is holding Lock B cannot get it and so never unlocks Lock B. If you acquire the locks always in the Lock A then Lock B direction, then you can prevent this problem from ever occurring.
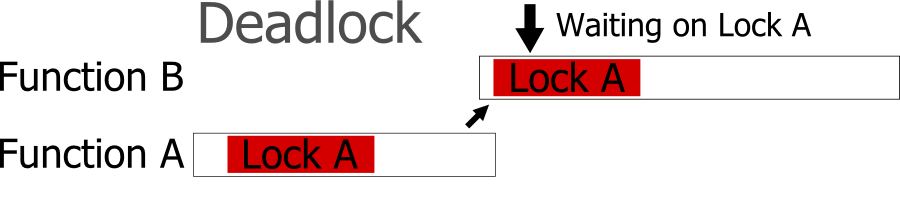
Another cause is simply attempting to use the same lock in multiple places, but you have code that calls to lock multiple times without a resulting unlock. You can easily design a re-entrant mutex that can handle this sort of use case if desired, but make sure that this behavior is what you want.
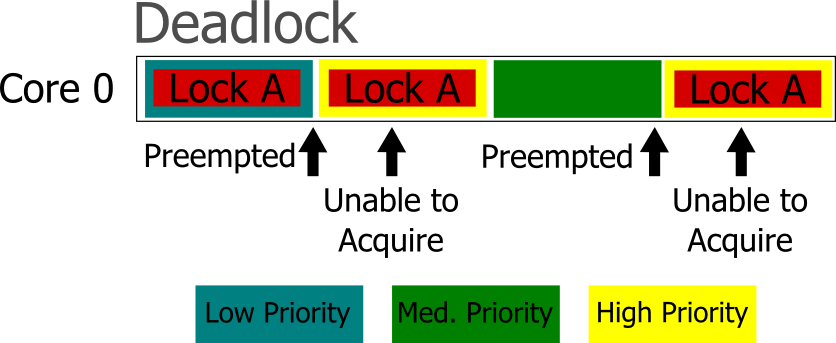
The final case that I will cover is likely the hardest to ascertain. When you have multiple threads of different priorities, you need to be careful when it comes to sharing locks. If you have a case where there is low priority, medium priority, and high priority thread, and the low and high priority threads both execute in the same critical section, then you need to be wary of priority inversion. If the low priority thread gets the lock, then gets preempted by the high priority thread, then the high priority thread will not be able to acquire the lock. So the execution will then fall to the medium priority thread (assuming the high priority thread isn’t busy waiting). This isn’t just some idealistic fabrication, it happened to the Mars Pathfinder. There are certain techniques that an OS might use, such as random boosting in Windows, that can help avoid this situation for you.
Lock-Free
When using atomic operations, we are also forcing a linear execution on our program, but in a much smaller scope. However, they do not fall prey to the things that can go wrong when using locks. Therefore, if we are not using any locks, then our program will always be able to advance. If our algorithm is guaranteed to never wait (even if it has to repeat some of its work), then it is considered a lock-free algorithm. Another way of thinking about it is if you were to arbitrarily pause any thread that is in your algorithm, it will not affect any of the other threads in there.
However, when dealing with lock-free algorithms, even though you do not need to worry about deadlocks as described above, you have a whole new set of problems. The main issue when writing code that doesn’t force linear execution for large sections is that almost anything can happen at anytime. When thinking through the code, you have to take into account that any other thread can come along and perform operations, such as changing a variable, adding / removing a node, or reorganizing the data. Because of this, it is common with lock-free algorithms to continuously test the assumptions before performing an action. If the assumed state is incorrect, then lock-free algorithms typically will loop and repeat their work until they can safely proceed. So, if an area of code has low contention, then using locks might actually lead to faster execution.
However, just testing the state isn’t without its caveats. One particularly nasty thing that can happen is known as the ABA problem. The idea here is that even if you are making sure that you are operating on the same address, by testing it with a Compare-And-Swap atomic action, it can still fail. If the address was recycled in some way (such as being deleted than allocated again, or popped then pushed again) then even though it is at the same location, it is not the same data. This can lead to crashes or lost data, and is very difficult to track down due to the fact that it can be extremely rare.

Wait-Free
Now, if you have an algorithm that will never repeat work and will always advance, then you have a wait-free algorithm. Because of their properties, they will always finish in a fixed number of steps. These can be exceedingly difficult to implement and it is rare to actually see them in use, though technically any algorithm can be translated into a wait-free one. Unfortunately, their performance is typically slower than their lock-free counterparts (though sometimes they can beat the lock-free one under certain circumstances). This means that for games, where performance is typically the highest goal and the number of threads is low, lock-free algorithms are generally the best option for highly threaded, time-critical areas.
Final Considerations
Never underestimate the power of a “good enough” solution. Because multi-threaded programming carries with it a high chance of hard to detect bugs, a tiny bit of performance tradeoff for a more stable codebase can definitely be worth it. Therefore, it is actually good practice to start with using simple locks to protect shared data. Then, when you are certain that those locks are a bottleneck, investigate into lock-free solutions. Also, because writing good lock-free algorithms can be difficult, it is usually a good idea to keep an eye out for already implemented libraries that you can make use of. These will help reduce possible implementation errors, since simple tests might fail to catch all the problems that can occur. Especially since the issues can be very dependent on rare, timing specific situations.
It is also a very good idea to redesign your code so that you minimize the areas where multiple threads can interact with each other. This gives you the benefits of parallelism without many the issues that can occur (such as all those described earlier). We will look at ways to do this later in the series, but I wanted the reader to first be familiar with some of the difficulties that can come with multi-threaded programming. That way, if you encounter a situation where you have to worry about multiple threads executing on the same data, you have a good grasp of the problem space going into it.

Next Time
For the next post, we are going to look at a basic locking queue implementation. For the post after that, we will then see a lock-free queue implementation where I will cover why we need to make the changes that we did in order to convert it. For the following post, we will see if we can optimize the lock-free queue further, and some pitfalls to watch out for while doing so. Because of the difficulties with wait-free algorithms and the fact they typically don’t have much real-world benefit, we will not be covering those further.
Further Reading
If you want to read some more about locking, lock-free, and wait-free algorithms, feel free to check out the following areas:
- Preshing on Programming: An Introduction to Lock-Free Programming
- Lockless Programming Considerations for Xbox 360 and Microsoft Windows
- Bruce Dawson: Lockless Programming in Games
- Atomic<> Weapons: The C++11 Memory Model and Modern Hardware
- The Art of Multiprocessor Programming
- Is Parallel Programming Hard, And, If So, What Can You Do About It?
Next Post – Multi-Threaded Programming 4: A Locking Queue Implementation
Multi-Threaded Programming 2: Communication
You can also view this post on AltDevBlogADay!
The next step in learning about multi-threaded programming is going to involve seeing how threads communicate with each other. This is important so that it is understandable why many of the pitfalls when programming with multiple threads exist. I am going to stick with x86-64 based architectures for simplicity, but this is pretty applicable to all computing devices from my experience.
If you want to read up on other things that I have covered, then here is my previous post in this series:
Reading From Memory
So to start, let’s see what happens when a thread reads from memory. First, the processor will request a load from a specified memory address to store it in a local register. Since we are just dealing with a single process, I will avoid discussing the details behind virtual memory addresses and TLB, so just consider this a physical memory address.
This will then hit various data caches to see if this address exists in them. It is actually pretty common for a modern multi-core chip to have 3 levels of cache. With each level of cache, you get more storage available, but also longer access latency. These later caches can even be shared by multiple cores. We will go with the worst case scenario in that the address does not exist in any of the caches, which is known as a cache-miss. If it had, then it would be called a cache-hit and the data at that address would get to the core much faster.

In this case the L1 and L2 caches are specific to each core.
So after the address has made it all the way to the main memory of the computer, the data at that location begins its long trip back to the processor. Note that in the real world with virtual memory addresses, the location of the data could actually be on the hard drive, meaning that we need to wait for that slow thing to locate what we need before we can get access to it. Along the way back to our waiting core, each level of the cache is updated to have that data stored, so that any future access to it will be much, much faster.
Because each trip outside of the caches is slow, a single read will pull in data around the address requested. The size of this data is equal to the size of a single cache line, which is typically 64 or 128 bytes. The cache works by dividing memory up into aligned cache lines and storing those, but the specifics of how that might occur is beyond the scope of this series. It should be noted that in the case of any shared caches, if one thread pulls in data into the cache that it will be available for any other threads that might also need to read that data. So it can actually be useful if multiple threads are reading from the same data since the first thread will pull it into the cache and then the other threads can benefit from that. Though since cache layout is pretty specific to the type of processor (and the core that is executing your thread can potentially change unless you adjust the affinity correctly), this type of optimization can be difficult to actually implement.
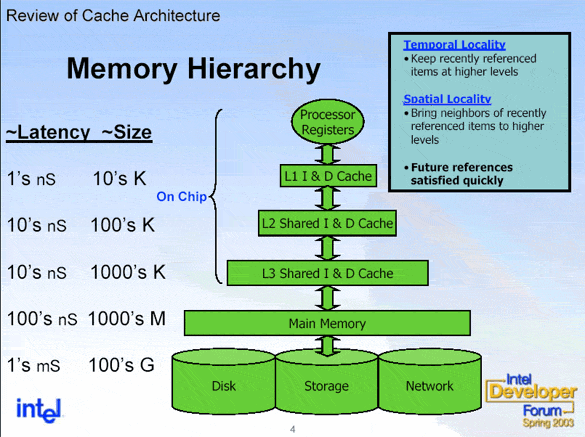
I stands for Instruction, AKA code. D is for Data.
Writing To Memory
A program is pretty useless without writing something back to memory, so let me briefly cover what happens when a thread does just that.
It starts by specifying what data to write and specific memory address to write to, just like with the read earlier. The core will execute this write instruction (typically referred to as a store), which will be put on the memory bus to head to the caches. The caches will snoop the bus to see what address is being written to, and will update their entries accordingly. Only after the cache line that has the updated data needs to be replaced will the updated data finally make it to main memory. Fortunately, the thread that executed the write instruction doesn’t need to wait until the write completes before moving on to the next instruction.
One thing you do need to keep in mind is that with modern Out-Of-Order CPUs (and compiler optimizations), the order that you write the code in is not necessarily the order that it will execute in. While there are guarantees in place that will make the code functionally work the same as you initially told it, these do not apply when it comes to other threads. This is done to compensate for the delays that occur due to the time it takes for data to come from (or to) the cache. You do have the ability to put in memory barriers (also known as memory fences) that will signal to the compiler and the processor to not do this. This will become important later on once we have multiple threads in the mix since we will need to coordinate their actions and enforce the order that certain steps perform in. Also note that you should not confuse memory barriers with the keyword volatile, which in terms of multi-threading in C/C++ (which I will be using for examples in later posts) doesn’t help you accomplish this.
When multiple threads are writing to the same data location, whoever executes last is typically the winner (the actual behavior may depend on the underlying hardware). However, since threads are controlled by the operating system, guaranteeing which one that will be is nearly impossible. So you have to be extremely careful whenever you have multiple threads writing to the same area. Fortunately, we have a few tools that will help us do this, which I am going to cover next.

Atomic Operations
Finally, we are going to touch on a vital piece of communicating between threads, and that is atomic operations. As I just mentioned, when dealing with multiple threads operating on the same data, guaranteeing the order of operations is nearly impossible. Even if one thread is executing ahead of another, that thread can be preempted and then fall behind. Naturally, this can happen at any time completely outside of your control. Additionally, a thread can stall waiting for a read or write operation (say one thread hits the cache and another doesn’t). So you can never rely on a thread being first or multiple threads being organized in any such fashion without synchronization abilities. Atomic operations fill in this important role. These are implemented directly on CPUs as operations that cannot be interrupted (performing multiple operations in a single instruction with specific constraints), so they will operate in a serial manner regardless of other thread or operating system interference.
The fundamental atomic operation is the Compare and Swap. What this does (as the name implies) is that it performs a compare of the data before swapping it with different data. This is so you know that you are operating on data that has not changed (since another thread could have come by and beaten you to the punch).
Let’s look at a simple example of an increment using some pseudocode. Assume we have a Compare and Swap function called CAS that returns a boolean indicating whether it was successful:
// our function signature
bool CAS(void* AddressToWrite, int CompareValue, int SwapValue);
static int x = 0;
local int y = x;
while (CAS(&x, y, y + 1) == false)
{
y = x; // fetch the new value
}
Assuming this is in a function that can be called by multiple threads, we need to protect against the possibility that any other thread can change the value of x from the time we read it into our local variable to the time we increment it. If that does happen, then we need to read in the new value and try again, keeping in mind that we can be behind yet again due to some other thread. However, we should eventually succeed unless we find ourselves in some situation where other threads are continuously hitting this section of code, which in a normal program would be neat impossible.
Also using our Compare and Swap function, we can implement a simple mutex lock. We can have a variable that will act as the lock value. Then we can attempt to acquire the lock by seeing if that value is 0 and then setting it to 1, and releasing the lock in a similar but opposite manner. Some psuedocode for those is below.
Lock:
static int lock = 0; while (CAS(&lock, 0, 1) == false);
Unlock:
// technically this should always succeed assuming // we successfully locked it in the first place while (CAS(&lock, 1, 0) == false);
Next Time…
For the next post in this series, we are going to look at a couple of different simple algorithms and see how we can use what we have learned here in order to make them operate in a multi-threaded (or concurrent) manner.
If you have any interest in other areas dealing with multi-threaded programming, please let me know in the comments and I will see if I can make a future post answering any questions or topics you would like covered. Thanks for reading!
Next Post – Multi-Threaded Programming 3: Locking, Lock-Free, Wait-Free
Multi-Threaded Programming 1: Basics
You can also view this post on AltDevBlogADay!
This will be a series of posts in which I will cover a good portion about what I have learned in terms of multi-threaded development in the realm of video games. I am writing this since I have been inspired by informative series of posts here such as Alex Darby’s Low Level C/C++ Curriculum. So my goal is to explain how multi-threading works at a low and high level, as well as looking at a few common scenarios that can benefit from these techniques. I might even touch on a few situations you can get yourself into and some techniques for debugging them. I hope you will enjoy reading about it as much as I enjoy discussing it.

I am not the first person to make this joke…
What is Multi-Threading?
Lets start at the very beginning and cover exactly what a thread is and why having more of them (up to a certain point) is a good thing.
Every program that runs on a modern computer (such as your PC, game console, or smartphone) is a process. These can have child processes as well, but for simplification I am not going to cover those. These processes can have a number of threads associated with them. These threads are what execute the actual code for the running program. Threads run code independently but share memory. This allows them to operate easily on the same data but perform different calculations. The fact that they share memory is the powerful, double-edged sword of their functionality.
A modern CPU is typically composed of several cores. Each core can run one thread at a time (though hyper-threading can sort of run two interleaved, but I am going to ignore that for simplicity). The way that a computer with a single core simulates multitasking is that the operating system can switch between threads at will. So while only a single thread can be executing, enough are getting a chance that everything appears to be running simultaneously. This means that if your program wants to make full use of all the available computing resources your CPU has, you don’t want to have more threads than it has cores, since you will be switching between executing your own threads. This switching between executing threads is called a context switch, and while it isn’t exorbitantly expensive, you still want to avoid it as much as you can to achieve optimal speed.
The main parts of a thread are the program counter and other registers, the stack, and any accompanying local data storage. The program counter keeps track of what part of the code it is currently executing. The registers keep track of the current values of the executing code. The stack holds any values that don’t fit in the registers. And the local data is program specific, but generally keeps track of data that is local to that thread. This local storage is accomplished via a lookup table, managed by the OS, that will have each thread look up into its specified index to see where its data is kept. In short, this allows you to have variables that you can access like a global, but are in fact unique to each thread.
So, taking into account all of this, multi-threaded programming is when you use multiple threads in your program. Typically, you are doing this so that you can execute your program faster than you would using a single thread. Another common usage is to separate out your UI from the rest of the program, so that it always feels responsive. The difficulty in doing so lies in designing the systems in such a way that they can make use of multiple threads in these manners.

Show me your cores!
Why do we need it?
In short, we need this in order to make the most use of the available resources. But the real question is more likely, “Why do we need it, now?” and this is due to the trends in computing.
Since the dawn of the CPU, as years have gone by hardware manufacturers have been able to increase the speed of computers by increasing their clock rate. However, a little less than a decade ago, consumer products topped out around 4GHz for awhile. A lot of this was likely due to the effects of electromigration since CPUs were getting smaller and also as the frequency increased they were releasing more heat. While we are now getting processors that are reaching 5GHz for consumer use, that left ten years where chip designers had to think laterally. And this means that one of the key innovations was putting more CPU cores onto a single chip. So no longer could you expect your games to be faster just by putting in new hardware, you had to design the game so that it could work well using multiple threads running on multiple cores.
One of the first areas where multi-threaded computing required games to adapt was with the release of the Microsoft Xbox 360 and Playstation 3, and for two similar but different reasons. The 360 had three cores with Hyper Threading technology (HTT), meaning that it could conceivably run six threads in parallel. The PS3 had a single core with HTT, and seven Synergistic Processing Elements (SPE), in a new architecture called the Cell Broadband Engine. The 360 had unified memory, so that all the threads could access all the memory. This made it easy to implement multi-threaded applications since you didn’t have to worry about who could access what, unlike with the PS3. Each SPE there had only a limited amount of memory that it could make use of, meaning that as a developer you had to carefully design your algorithms to take this into account.
Also, from a pure performance standpoint, the CPUs in the consoles were slower than their traditional desktop counterparts. While they were clocked similarly in speed, they were simpler chips that didn’t have a lot of the fancier technologies such as Out-of-order execution that made the most of the available power. So this forced developers to cope with multi-threaded strategies in order to make their games stand out amongst the rest.
In the desktop world, multi-core CPUs were quickly becoming the standard, but it appeared that developers were slow to adopt their programs to make use of the additional cores. A lot of this was likely due to two main factors. First is that the desktop world has a much broader range of hardware to support, and so they tend to design with the lowest common denominator in mind. Meaning that they wanted to support older systems that likely only had a single core available. Second is that multi-threaded programming is more difficult, and it takes a different approach to handling it. Couple this with the fact that a lot of game teams tend to reuse technologies, so in order to take advantage of multiple cores a lot of things would have to be rewritten. Also, graphics tended to be a big bottleneck in games, and submitting all the stuff for the GPU to draw was restricted to being done in a serial manner by the APIs (DirectX or OpenGL, typically). Only with the latest versions of the APIs (released only a few years ago) has it really been possible to make the most use of all the available cores in modern CPUs. And now with the latest generation of consoles upon us, developers have no excuse to not use heavily multi-threaded game engines for the top tier games.
Next Time…
For the next post in this series, I will cover how communicating between threads works on a hardware and software level. This is important to understand what is exactly going on with the CPU in order to avoid many of the potential pitfalls that are inherent in multi-threaded programming.
If you have any interest in other areas dealing with multi-threaded programming, please let me know in the comments and I will see if I can make a future post answering any questions or topics you would like covered. Thanks for reading!
2013 Year in Review
A Year of Challenges
I would definitely label this year as a year of challenges for my family and myself. The biggest event would definitely be selling our condo of six years and purchasing a house where we hope we stay at least until the kids move out. The condo where we were living (and is starting to feel like a distant memory now) is only a two bedroom. With our two kids sharing one bedroom and only getting bigger, I wanted to give them their own rooms. My son was also going into kindergarten in the fall, and I wanted to be able to move before he started, so that he wouldn’t have to go through changing schools. Mortgage interest rates were low and housing as a market was starting to recover, so it was a good time to buy. Unfortunately, condos, while on the rise, were by and large still depressed compared with homes and their recovery, so it was a bad time to sell a condo. That led my wife and I to make a difficult decision, as we would have to accept taking a loss on our condo and thus not being able to afford as much of a house as we would like, or deal with staying in our condo for several more years, where we might end up facing a similar situation years down the road anyway if housing rose faster than condos. So we decided to embark on the crazy ride of simultaneously selling and buying real estate.
 On Selling
On Selling
We decided to use Angie’s List in order to find a listing agent to sell our place. We definitely wanted to select someone from the area, who could easily represent Oak Park to anyone new to the area (and who would be familiar with the local market). After narrowing down the list and interviewing those remaining, we decided on Gary Mancuso. We chose him because we also weren’t entirely sure if we were going to sell or rent our condo, and he was willing to do either. Though after finding out from the bank what they would loan us if we kept our existing mortgage, combined with FHA and conventional loans rules when it comes to condo buildings that have a non-owner-occupied units, we figured that renting wasn’t a very viable option. Plus, I admit, I wouldn’t really look forward to becoming a landlord on top of everything else. Gary also beat out the rest because he strongly emphasized a good web presence, offered virtual tours with a floorplan, used a professional photographer, and charged the same rate as everyone else. I think he was definitely instrumental in us getting an offer less than a week after finally listing the place.
Before we could get to that point, however, we had to get the place ready. We had been in there for nearly six years and had two small children, so the place wasn’t in the greatest of shape (but fortunately nothing some Spackle and fresh paint couldn’t fix). There was also the benefit of the basement where we had a good amount of storage space, so we boxed up a lot of the stuff we didn’t need on a day to day basis and put it down there. A good rule of selling is to get rid of excess stuff, since the people buying the place aren’t going to get it, so they don’t need to see it. After spending about two months or so on nights and weekends repairing the little odds and ends and deep cleaning the place, we were ready.
Our first offer naturally came in less than what we listed for, so after a little bit of haggling, we eventually compromised in the middle. It was less than I wanted, but the first offer is generally the highest, and the buyers were solid in terms of the loan department, so I figured it was the best we were going to get. We were worried about how long it would take for us to find a house that we wanted and could afford, so we decided on a closing date that was several months out. The hope is that it would give us plenty of time to find a new home, since we couldn’t go looking officially until we got that offer on our place.
 On Buying
On Buying
We decided to go with a buyer’s agent on purchasing our home, since I was hoping that it would alleviate any potential conflicts of interest that a normal real estate agent would have. After checking out a few, we settled on Jeff Kropp. He was very helpful for us, though I am not quite sure how much of a benefit we got from him being a buyer’s agent. But he definitely worked with us and helped us through the stressful process.
The problem with buying while you are selling is that you are on a time-limit. Considering that we want to spend twenty years or so in the house we are looking to buy, only having a month to look for it is a bit nerve-wracking. We were able to get a little more time, however, by pushing the closing date for our condo out to a later date. But still, even with that extra breathing room it is a tense experience as the good homes get snatched up quickly so you don’t have a lot of time to think about your decisions. So that leaves a lot of sub-par houses sitting on the market that you can check out, which also isn’t encouraging.
One case where this hit us was with our first pick. After checking out the market for a week or so, the houses in our initial price range weren’t anything to be excited about. So we decided to stretch our budget a little more and this popped up a few that we would be happy with. After checking those out, and eliminating the ones that were okay in the photos, but horrible in person, we were able to narrow it down to two. Of these two, one was a very large house with a roof that was being sold “as-is”, and a smaller house with all the modern conveniences plus a lower listing price. Being a bit worried about what we could reasonably afford, I was leaning towards the smaller house. My wife, thinking of daily life and kids that were only going to get bigger with time, wanted the bigger house. After a few days of discussing it and visiting the homes again, I started to agree with her. So we went to put an offer on the house and found out that someone had beaten us to the punch. It was extremely frustrating since there was no indication that this had happened until after our agent spoke to theirs. For a brief moment we considered trying to engage in a bidding war, but came to our senses before it came to that.
So with our emotional wounds still fresh, we trekked back to look at new homes since we didn’t have time to wallow in self-pity. Fortunately, we came across a house that had only been on the market a week that was similar in layout as the smaller home we liked before (though fortunately a bit bigger). Not wanting to be second place again, we put a bid on the house after only seeing it once. And once again, we found out that there was a previous bid already. Fortunately for us, the sellers weren’t entirely pleased with the first bid and hadn’t accepted yet. So we did find ourselves in a slight bidding war, but we put in an offer for the most we were willing to afford and stuck with that, which was thankfully accepted. We had a bit of back and forth after the inspection, as there were a few problems with the home, but after several weeks of negotiations, we were able to reach a compromise.
So with the condo ready to be sold and the house ready to be bought, we just had a wonderful task of packing up all our stuff and finding someone willing to move it. Fortunately, we had some friends to help us out with the packing, making that a bit easier in the final days (as we sealed the last box only hours before the movers were to arrive). And Under One Roof was willing to come by the day before we closed and pick up our stuff, then deliver it to our new place the day after we got the place. Overall, moving turned out to be one of less stressful parts of the experience, thanks to the help we got from everyone. Though you never quite realize just how much stuff you accumulate over the years (especially with two small children), until you try to move all of it.
 On Owning
On Owning
Now that we are proud homeowners of our own little place, we are solely responsible for maintaining it. It is nice no longer having other families that we have to worry about when our kids are being extremely loud, and I admit that I am glad no longer being the President of the Condo Board as well. However, there are always things that the house inspection doesn’t catch (and other things that just break anyway). Our first issue came with the garage door. After living in our place less than a week, after arriving home and parking the car in the garage, while we were getting out, we heard a loud snap and something hit my wife in the face. Our garage door was installed with extension springs, and one of these had just broken. Fortunately, the broken piece had lost all of its momentum by the time it hit my wife, so no damage was caused. I went the next day to the hardware store and bought some new extension springs to fix that up. Unfortunately just after doing so, the wire connecting to the garage door snapped, so I knew I needed to get some professional help. So after only a week at our new place, we had a new garage door, tracks, and torsion spring system installed.
One of the items that came up during the home inspection was that we had knob and tube wiring in our attic. While having original stuff on a 100-year old house can be desirable, wiring is not one of those cases. There were also a few other things that we wanted looked at while we had electricians out, such as fixing a few light fixtures, installing another light fixture in the utility room, and moving the light-switch from behind the refrigerator. The electricians thought that the knob and tube wiring would only be in a small area, but it turns out that most of the second floor was being powered by it. Upon replacing most of it and putting it on an actual grounded connection, the fuse box was being tripped repeatedly. So they had to come out two more times to finally fix that and get everything working again.
Winter this year also hit hard and suddenly, which stressed our heating system. I was aware ahead of time that the piping to our boiler wasn’t fixed properly when a new boiler was installed several years ago, but because of it there is excess water in the pipes which is causing several leaks on colder days from our radiators. Plus the radiator in our bedroom isn’t leveled properly so it is retaining water leading to loud banging. And finally, we discovered a crack in our backward radiator so that needs replacing. While we haven’t scheduled this work yet due to people who are without heat taking priority, it will be another chunk of change I wasn’t planning on spending. So add all the work to the house, the fact my car hit 60k miles and needed that checkup, plus the general holiday spending (which occurred before the heating issues), and it has been a rather expensive year. But I am confident we will get the remaining issues sorted and everything back to a better state.
 On Next Year
On Next Year
So with all that mostly in the rear-view mirror, I am hoping that next year will be a bit more uneventful. Work has been and I expect it to continue operating mostly smooth. The kids are enjoying school and I hope they will continue to do so. I am not sure how we are going to handle the summer now that my son is in kindergarten and no longer in preschool, but we will figure something out. We don’t have any big plans since just getting a house was daunting enough, and with all the work done and soon to be done, money is definitely a concern. But I think that things should be smoother from here on out and that we have many good years ahead of us here. And with some downtime over the holidays, I was able to hang up most of the pictures of our family on the wall so that we can keep turning our new house into our new home.
Super Mario Cuckoo: Initial Framework
For a quick recap, you can read the introduction to this series here: Making a Game for My Kids

Initial Framework
In all the projects that I have started before, I typically begin with a blank slate. This is likely due to my love of engine code and understanding the low level of how everything works and fits together. However, this does mean that I have to implement everything myself, and since I start pretty much each project with nothing, that means I spend a lot of time rewriting the same things. In addition, since each time I am generally trying some new technology or methodology, this means that I am often not able to reuse code that I have written before. Though since I am typically doing the project to learn and not necessarily to produce something, this usually isn’t too much of an issue. However, this time I actually aim to complete a game (or at least a full level or two). So I am finally looking at a couple of third party libraries to help with some of the development for the parts of this that I really don’t want to bother with anymore. I will detail these in addition to the selection of technologies that I am using, though they are more to facilitate development than actual learning tools. However, it is good experience to work with what other people have produced (and that are being used by several others) to get a good idea of other ways to design systems and APIs.
I plan on developing this for Windows, though my selection of technologies isn’t specific to this platform, so if things get far enough along I might port it elsewhere. After a recent computer upgrade, I have enough leftover parts to get another computer going, so creating something for Linux is a distinct possibility. Especially with the coming of SteamOS at some point, it might be a worthwhile exercise in the future. I will be using Microsoft Visual Studio 2013 Express since it is free and should be good enough for my needs (though they still don’t have a breakpoint window, which I find an odd omission). Since I am only planning on making simple 2D based games, I likely won’t need the tools for heavy threading work 🙂
For my general code architecture, I will be using a light object oriented approach. This is still early enough in development that I might switch it up and there is a good chance that I won’t really follow any one specific methodology other than KISS. Since I will be using a scripting language for heavy development for the first time, I am not quite sure the best way to approach things for gameplay, but that is part of the learning process.
I plan on keeping notes and details on my wiki here. Though I also plan on blogging about the development process along the way as well, so keep an eye on this space as well!
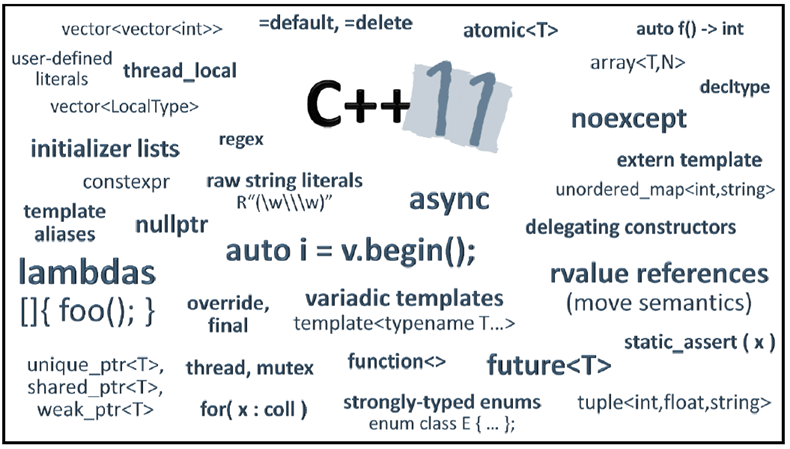
C++11
I chose to go with C++ over C# (or another language) because of my familiarity with it and the relevance it has with my job. In addition, the recent C++11 spec adds a lot of new stuff to it that I want to try out in some capacity. While a lot of this deals with threading stuff that I would love to try out, unfortunately that falls outside the scope of my current project. So most of the C++11 stuff that I am using mainly consists of a few niceties like nullptr and static_assert, but I can use a few core changes like their new pointer types: shared_ptr and unique_ptr.
Overall these are a good addition to the language and should hopefully make programming in C++ a little easier for newcomers, though I admit that I am struggling a little bit to change my mindset over to using them. Determining the best way to use them took a little bit of experimentation, as I initially sought to replace all pointers in my code with them. This quickly devolved into madness for me however, as I just couldn’t bring myself to change everything over since I knew a lot of it was just wasted effort on the computer’s part keeping track of all the bookkeeping. While realistically this likely wouldn’t have any noticeable performance impact due to the simplicity of my game, as an optimization-centric programmer by trade, it just didn’t sit well with me. I wanted to be able to get the benefits of the tracking without unnecessary cost. Fortunately this was easily solved by just making owning pointers be a type of smart pointer, and anything that I was just passing in a function to be used could remain a normal, dumb pointer.
The C++11 spec is pretty extensive in the amount of changes, so I am still going through it and deciding what might be useful to learn about and use (such as the move semantics). I will add them and update code as I see fit throughout the process.

OpenGL 4
I originally started with DirectX when I was learning graphics as a teenager (after failed attempts in DOS and while I got GDI working, it wasn’t exactly fast) and it is what I primarily use now. I used OpenGL primarily in college for my courses (universities love them some Unix), but haven’t really touched it much since. I messed around a little with WebGL when it was first coming on to the scene, but working with Javascript turned me off (that and the fact that IE wasn’t originally going to support it made me think it was unlikely to gain traction, though they have reversed their stance). So there is definitely a possibility that I might try to get the game on the web at some point, though it is just one of the many things I would love to do. First, though, I need to get something finished before I start considering what I would like to do next.
Back to the topic at hand, I decided to go with OpenGL since it has been making some strong strides as of late. With it having a strong grasp on mobile as well as a lot of smaller projects embracing it so they can more easily go multi-platform, OpenGL has been quickly becoming more relevant as a graphics platform. I must admit that I was actually a bit surprised given OpenGL’s sordid history. But with OpenGL 4 it seems they have gotten their stuff together on the PC front as well (and Valve saying that it is faster even on Windows never hurts). So I have decided to check out how things fair in their area nowadays.
Since OpenGL is only a graphics library, I need to get help in other areas to match some of the missing features in DirectX and XNA that I have gotten used to. This is part of where I really don’t want to reinvent the wheel and am opting for third party assistance. First I am starting with GLEW to handle the window initialization and all important extension loading to actually utilize the OpenGL 4 features. To actually load in my images for textures, I chose SOIL due to its simplicity and the fact that I was planning on using PNG files for the game. Finally, since I don’t want to have to write a math library, I selected glm to handle that part. As you may be able to tell, I am choosing simple libraries that only serve my specific need. I figure this will make them easier to use and integrate into my game. These also appear to be pretty stable and are recommended by the OpenGL wiki, so I assume they are good quality as well.
![]()
Lua
I had always wanted to increase my repertoire my learning a scripting language. They are very useful and serve a good tool for quick iteration. My goal is to force it so that I need to code using script in order to complete the game. This should make learning easier as it will give me a project. I have a book on Lua that I have read before, but without actually programming anything to make use of that knowledge, it has been mostly forgotten.
The reason for choosing Lua is that it integrates easily with C/C++ and is a small, simple language. It is popular in game development for this purpose as well. It was being used in a project that I was working on at the time when I first wanted to learn it, but being in graphics I never really interacted with it much. It was used primarily for gameplay and those related systems. Designers would use this to be able to tweak behaviors and actions that were typically set up by programmers. This allowed them to change and update the game without always needing assistance. Of course, giving access to the game like this to designers also introduced bugs, and I did help fix a few of these later into development. But going into a script and fixing a few things is typically easier than learning a new language (especially since I had some guidance as to what to look for that might have been causing the issue).
However, this model where basic, and sometimes even advanced, gameplay logic is contained in scripts is a good idea overall (assuming you have designers that are somewhat competent when it comes to programming, though always expect bugs when programming is involved). I am planning on doing something similar so that I can hopefully introduce my children to programming. And since scripts are interpreted immediately, it gives the kids instantaneous feedback when they see the changes in the game right away. I hope that it will be much easier for their patience and attention level that way.
Next Steps
So that is the initial steps that I am planning on doing when I approach making this game. So far I have only rudimentary progress where I have a single 2D image up on the screen and can move the camera around to view it, but it is a start. I have the Lua library integrated, but do not quite have it doing anything yet. Hopefully with the upcoming holiday break, I can spend a little more time building out the next parts of the game. I need to get a basic game tile rendering system going, so that I can display the backgrounds. It would be good to get a character that can jump around in those levels too. And of course, I need to start writing some Lua scripts to control various things. All in all, I am excited about the project and hope that I have time and motivation to stick with it in the coming months.
Making a Game for My Kids
Parenting and Video Games
As a parent with children that are now of the age where video games are fun and something they enjoy doing, it is my responsibility to help guide them so that they play and experience appropriate stuff. As a lifelong fan of video games, I would like for my children to appreciate them as I do. If I let them play games that they didn’t find fun or weren’t suited to their age, I might turn them off from them. Naturally, I started with the basics with Super Mario Bros for the original Nintendo, but played on the Nintendo Wii (though I should have a working original copy with the system in a box in the basement). So naturally, they are big fans of Mario and Luigi now (and my son and I even went as Mario and Luigi for Halloween once). I even convinced my son to go see Wreck-It Ralph in theaters because Bowser was in it. Though during the movie he was constantly asking me where Bowser was when he wasn’t onscreen.
Kids are also very imaginative sorts. After playing games for a bit, when I make them turn it off they will often reenact what they were just doing when playing by themselves (same goes for movies and tv shows). While doing this they will often change stuff around a bit, though I am not sure whether this is due to poor memory, physical constraints, or they are just having fun with it (likely a combination). Anyway, for whatever reason, my son came up with an idea for a game. He calls it Super Mario Cuckoo and you play as Bowser instead of Mario.
Side Projects and New Technologies
As a game developer, there are always new technologies that are out there. I particularly enjoy working with graphics, but it is also good to brush up on other areas of game making as well. I have previously played around with C# and XNA, though with XNA being deprecated and no longer supported, I looked into alternatives like SharpDX. This was a good to work with, but I had wanted to mess around with the new C++11 standard stuff. I also have been paying attention to OpenGL coming back in a pretty big way with mobile (and soon to be the web), and while I wanted to stay with PC development, it would be good to familiarize myself with it a bit more. Finally, I know that I am sorely lacking in my knowledge and ability with scripting languages. While there are many to choose from, I went with Lua because it is heavily used in the game industry and one that I had previously tried to learn. By making it a required part of the game that I am developing, it forces me to use it and thus gain the knowledge that I have been trying unsuccessfully to do before. Also, I hope that eventually that I can introduce my son (and daughter eventually) to programming and I think the fact that scripts can be updating very quickly will allow him a fun and easy introduction.
Ongoing Development
I admit that I have started many projects along the way and that I haven’t fully completed any of them. This is for a variety of reasons, such as a lack of focus or other priorities getting in the way. I hope that by doing this for someone else instead of just myself, it will keep my likely to stick with it to the end. I’ll also bring my kids on board to help with the development in some capacity, so that hopefully it can turn into something that we build together. This will likely take some time to do, so it might even be something they grow up with. But I hope it keeps their interest (and mine) and is something we can have fun with (and learn!) together.
Next time I post about this I will get into some details about the actual development.
Game Review: Septerra Core
Note: Game reviews will contain spoilers.
A Decade in the Making
I don’t recall how I first purchased Septerra Core, as it was literally over a decade ago. It was likely back in college, ordered off online before Amazon was ubiquitous, possibly from Ebay (though I believe I got it new). It would have been before I got my now main email address at GMail, and definitely before I realized the importance of archiving all the old emails. It definitely is amusing to think of all that has happened in the past ten years or more, but back to the relevance to my story. Septerra Core is an old game, and while using DirectX, backwards compatibility wasn’t always the greatest in the earlier versions. It is also a pretty long game (as they really could be back then, with lots of filler and backtracking and the like), so it took awhile to play through and probably got put to the side several times. As a college student, I also was able to get new OS discs for cheap, and so would routinely jump to a new OS from Microsoft whenever I was able. But at some point upon doing so, Septerra Core would no longer work, and so it was relegated to the “pile of shame,” referring to games you started but never finished.
It wasn’t for a lack of trying, as with upgrading to XP I would try compatibility settings in hopes that it would run and searched around for any new patches. But with Valkryia Studios going bankrupt and closing their doors. After a few years of trying, I eventually gave up. Unbeknownst to me, a patch was eventually released in 2006 that would address these issues, but by then I had more or less given up, though I did still have the disc in my possession just in case. Then one day several months ago, while looking through GOG, I happened to stumble upon the listing for Septerra Core. I noticed in the compatibility that it only lists XP and Vista, but looking through comments I ascertained that it would also work with Windows 7 64-bit, which is what I have installed. So, still unaware of the patch, I plunked down the $6 to purchase the game and blew the dust off my old saves (figuratively) and excitedly loaded up the game. And behold, it all worked! My last save file was dated October of 2002, meaning that almost ten years had passed since I had last been able to play this game, but due to the great people at GOG, I was able to finally finish it.

Western JRPG on PC
While coming from a western developer, this game has a much more feel of being inspired by Japanese style of RPGs, with strongly defined characters and a linear story. Naturally, having not actively played the game in quite a long time, I was pretty rusty on the story and what I was supposed to be doing in the game. Fortunately the internet is a great trove of information for this sort of thing, and after skimming through a few walkthroughs I was able to piece together most of the backstory. So, with some sense of what happened and a few clues about what to do next, I was finally able to start playing again.
The way that you play the game is controlled entirely by the mouse. You use it to lead your party around the maps and to give orders in battle. Enemies are seen wandering around on the map and the battles also take place there, in difference to older Final Fantasy style games. During battle, you have a gauge that fills up over time and has three levels that allow you to perform increasingly stronger attacks. It appears that the strength increases linearly, so you get a little bit of strategy in figuring out if you want to save up for a stronger attack with the possibility that it could miss (I generally favored ‘mid’ level attacks). You also have magic which is controlled by playing cards. With three people in your party, you can play up to three cards together to achieve a variety of effects. The main card determines the attack while the others act as modifiers, such as adding an elemental type or making it affect all. The magic uses up a shared resource, so you don’t have to worry about managing the magic levels for each individual member.

Old School Problems
It is interesting to go back and replay older games, viewing them through the lens gained by experience with more modern games and their conveniences. The pacing of this game definitely felt slow by today’s standards, with lots of waiting around for the ability to take turns during battle, followed by animations that seems sluggish and longer than needed. Maps were also padded to be larger than need be, and there were many cases near the end where I had to get so many keys in order to unlock doors to get more keys, to finally get where I was going. Plus after getting the treasure or killing the boss at the end, the wonderful walk of shame out of the dungeon (fortunately much faster in reverse, but with enemies re-spawning with each area change, still not pleasant). It is a testament to the progress of games design that these stand out so much nowadays.
While I do appreciate the art and the confines of the screen from those days left not much to work with, it still felt cramped and wandering around the map wasn’t too enjoyable since you could only really see about ten feet in front of your character. The particle effects were nice, but were pretty basic by today’s standards. And the characters have a bit of a “plastic” look to them. For the time it was really nice, but with all the advances in graphics we have these days it can be a little hard to watch at times.

Another Off the “Pile of Shame”
While the end was a bit of a letdown, I do have to say that I am glad I repurchased the game and was able to finally finish it. It is a bit eye opening to think about how technology is progressing and how our medium of storytelling and experience is so very tightly coupled to it. It is very likely that over time older games may become unplayable and it is a refreshing sight to see places such as Good Old Games working to preserve the history (and make a buck or two while they are at it). I enjoyed having the experience of playing a game over such a long period, and giving me time to think about all that had progressed during that time. Video games have come a long way, and I eagerly await to see where they will go from here on in the future. Plus, that is one more game off my pile of shame.