
Multi-Threaded Programming 2: Communication
You can also view this post on AltDevBlogADay!
The next step in learning about multi-threaded programming is going to involve seeing how threads communicate with each other. This is important so that it is understandable why many of the pitfalls when programming with multiple threads exist. I am going to stick with x86-64 based architectures for simplicity, but this is pretty applicable to all computing devices from my experience.
If you want to read up on other things that I have covered, then here is my previous post in this series:
Reading From Memory
So to start, let’s see what happens when a thread reads from memory. First, the processor will request a load from a specified memory address to store it in a local register. Since we are just dealing with a single process, I will avoid discussing the details behind virtual memory addresses and TLB, so just consider this a physical memory address.
This will then hit various data caches to see if this address exists in them. It is actually pretty common for a modern multi-core chip to have 3 levels of cache. With each level of cache, you get more storage available, but also longer access latency. These later caches can even be shared by multiple cores. We will go with the worst case scenario in that the address does not exist in any of the caches, which is known as a cache-miss. If it had, then it would be called a cache-hit and the data at that address would get to the core much faster.

In this case the L1 and L2 caches are specific to each core.
So after the address has made it all the way to the main memory of the computer, the data at that location begins its long trip back to the processor. Note that in the real world with virtual memory addresses, the location of the data could actually be on the hard drive, meaning that we need to wait for that slow thing to locate what we need before we can get access to it. Along the way back to our waiting core, each level of the cache is updated to have that data stored, so that any future access to it will be much, much faster.
Because each trip outside of the caches is slow, a single read will pull in data around the address requested. The size of this data is equal to the size of a single cache line, which is typically 64 or 128 bytes. The cache works by dividing memory up into aligned cache lines and storing those, but the specifics of how that might occur is beyond the scope of this series. It should be noted that in the case of any shared caches, if one thread pulls in data into the cache that it will be available for any other threads that might also need to read that data. So it can actually be useful if multiple threads are reading from the same data since the first thread will pull it into the cache and then the other threads can benefit from that. Though since cache layout is pretty specific to the type of processor (and the core that is executing your thread can potentially change unless you adjust the affinity correctly), this type of optimization can be difficult to actually implement.
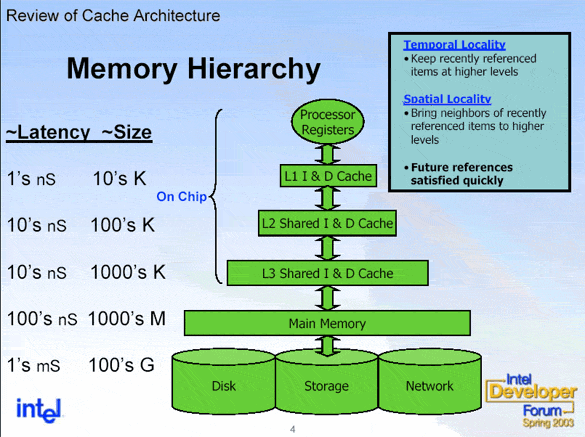
I stands for Instruction, AKA code. D is for Data.
Writing To Memory
A program is pretty useless without writing something back to memory, so let me briefly cover what happens when a thread does just that.
It starts by specifying what data to write and specific memory address to write to, just like with the read earlier. The core will execute this write instruction (typically referred to as a store), which will be put on the memory bus to head to the caches. The caches will snoop the bus to see what address is being written to, and will update their entries accordingly. Only after the cache line that has the updated data needs to be replaced will the updated data finally make it to main memory. Fortunately, the thread that executed the write instruction doesn’t need to wait until the write completes before moving on to the next instruction.
One thing you do need to keep in mind is that with modern Out-Of-Order CPUs (and compiler optimizations), the order that you write the code in is not necessarily the order that it will execute in. While there are guarantees in place that will make the code functionally work the same as you initially told it, these do not apply when it comes to other threads. This is done to compensate for the delays that occur due to the time it takes for data to come from (or to) the cache. You do have the ability to put in memory barriers (also known as memory fences) that will signal to the compiler and the processor to not do this. This will become important later on once we have multiple threads in the mix since we will need to coordinate their actions and enforce the order that certain steps perform in. Also note that you should not confuse memory barriers with the keyword volatile, which in terms of multi-threading in C/C++ (which I will be using for examples in later posts) doesn’t help you accomplish this.
When multiple threads are writing to the same data location, whoever executes last is typically the winner (the actual behavior may depend on the underlying hardware). However, since threads are controlled by the operating system, guaranteeing which one that will be is nearly impossible. So you have to be extremely careful whenever you have multiple threads writing to the same area. Fortunately, we have a few tools that will help us do this, which I am going to cover next.

Atomic Operations
Finally, we are going to touch on a vital piece of communicating between threads, and that is atomic operations. As I just mentioned, when dealing with multiple threads operating on the same data, guaranteeing the order of operations is nearly impossible. Even if one thread is executing ahead of another, that thread can be preempted and then fall behind. Naturally, this can happen at any time completely outside of your control. Additionally, a thread can stall waiting for a read or write operation (say one thread hits the cache and another doesn’t). So you can never rely on a thread being first or multiple threads being organized in any such fashion without synchronization abilities. Atomic operations fill in this important role. These are implemented directly on CPUs as operations that cannot be interrupted (performing multiple operations in a single instruction with specific constraints), so they will operate in a serial manner regardless of other thread or operating system interference.
The fundamental atomic operation is the Compare and Swap. What this does (as the name implies) is that it performs a compare of the data before swapping it with different data. This is so you know that you are operating on data that has not changed (since another thread could have come by and beaten you to the punch).
Let’s look at a simple example of an increment using some pseudocode. Assume we have a Compare and Swap function called CAS that returns a boolean indicating whether it was successful:
// our function signature
bool CAS(void* AddressToWrite, int CompareValue, int SwapValue);
static int x = 0;
local int y = x;
while (CAS(&x, y, y + 1) == false)
{
y = x; // fetch the new value
}
Assuming this is in a function that can be called by multiple threads, we need to protect against the possibility that any other thread can change the value of x from the time we read it into our local variable to the time we increment it. If that does happen, then we need to read in the new value and try again, keeping in mind that we can be behind yet again due to some other thread. However, we should eventually succeed unless we find ourselves in some situation where other threads are continuously hitting this section of code, which in a normal program would be neat impossible.
Also using our Compare and Swap function, we can implement a simple mutex lock. We can have a variable that will act as the lock value. Then we can attempt to acquire the lock by seeing if that value is 0 and then setting it to 1, and releasing the lock in a similar but opposite manner. Some psuedocode for those is below.
Lock:
static int lock = 0; while (CAS(&lock, 0, 1) == false);
Unlock:
// technically this should always succeed assuming // we successfully locked it in the first place while (CAS(&lock, 1, 0) == false);
Next Time…
For the next post in this series, we are going to look at a couple of different simple algorithms and see how we can use what we have learned here in order to make them operate in a multi-threaded (or concurrent) manner.
If you have any interest in other areas dealing with multi-threaded programming, please let me know in the comments and I will see if I can make a future post answering any questions or topics you would like covered. Thanks for reading!
Next Post – Multi-Threaded Programming 3: Locking, Lock-Free, Wait-Free